接触过图像识别的都知道,什么RNN,CNN,YOLO都是机器学习领域的,今天要学习的就是CNN(Convolution Neural Network卷积神经网络),专门被用在影像上。
Fully Connected Layer全连接层,网络结构很密,弹性大。
  一张彩色图片是三维的Tensor,包括有:高、宽、channel。这个channel就是R(Red)、G(Green)、B(Blue)三种色彩。假设有一张 100×100 的彩图,就可以把它看作是矩阵形式,也就是 100×100×3 的矩阵,把 100×100×3 的数值拉直变成一个向量,输入到network里面去,可以得到输出。
  那么这应该是一个什么network呢?模仿我们人类识别物体的步骤,我们可以看一小部分特征,就可以判断是什么物体;还有一个问题就是不同品牌的物体,所具有的特征并不是都设计在同样的位置。如此,得到两个小问题:
Observation1:很多重要的Pattern,只需要看小范围就知道。
Observation2:同样的Pattern会出现在不同图片的不同区域。
  针对以上两个 observation ,可以对全连接层网络做出简化。
简化1:Receptive field接受域
- 考虑所有的channel,一般只说高和宽,也就是卷积核的大小; kernel size:3×3
- 每一个receptive field都有一系列Neurons去感知它;
- 步长stride也是超参数,一般步长不会大于卷积核的宽,卷积核彼此之间会有重叠部分。当移动超出边缘时,超出的部分称为padding,通常使用全零补充法。
简化2:share Parameter权值共享
- 虽然权重是一样的,但是每个神经元的输入是不一样的,所以输出也是不一样的。两个Neurons共用同一组参数,这组参数称为filter。
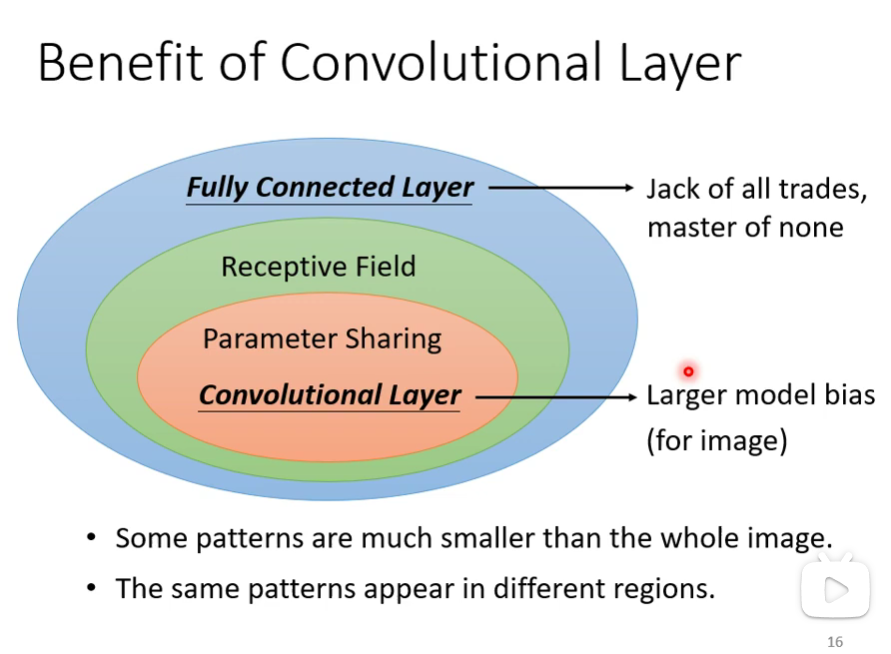
  这样简化以后,CNN的Model的bias比较大,Model的bias大不一定是坏事,当Model的复杂度很高的时候,比较容易过拟合,Fully Connected Layer可以做各式各样的是事情,可以有各式各样的变化,但是它可能没有办法在任何特定的任务上做好。
  Convolution Layer是专门为影像设计的,虽然Model bias很大,但它仍可以做的很好,这个在影像上不是问题,但是在影像之外的任务,就要小心了,要看那些任务有没有影像用的特性。
\par\par
Pooling池化
  我们人是很聪明,一张图片,把像素点减少(100×100 $\rightarrow$50×550),我们依然可以识别出物体。感觉有点像近视眼,那么是不是也可以把它运用到CNN上呢?这个就是池化(Pooling)。
- 本身没有参数,不是一个layer,里面没有weight,没有要learn的东西,比较像是一个Activation Function,它就是一个operator,都是固定好的操作。
- 作用是使图片变小,减少运算量。但是近年来,硬件算力普遍提升,不少人开始不做Pooling
  其中有一种做法是:Max Pooling最大池化。做完convolution以后,把结果2×2(或者3×3)组合起来,选取其中最大的那个数值作为代表,组合起来。当然还有Min Pooling等方法。
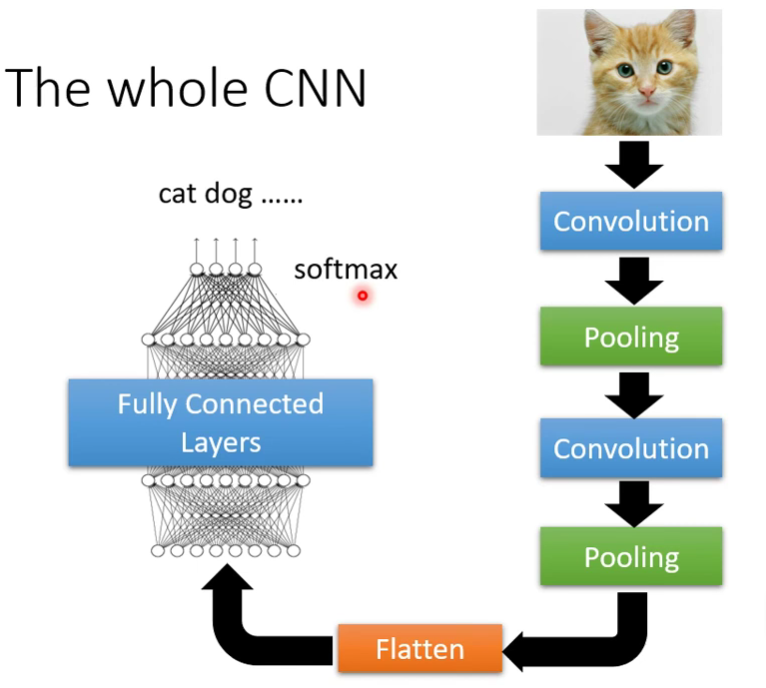
总结起来就是:局部感知,权值共享,多核卷积,空间下采样
注:CNN并不能处理影像的放大缩小,因为放大缩小以后,把它拉长成向量的话,里面的数值是不一样的。