经过上一节MLP-1(步骤),对机器学习的步骤、一些专业名词有了一定的了解。如果现在需要你来改进一个机器学习,我们从哪里入手呢?本文就简单地带你来攻略“她”吧~
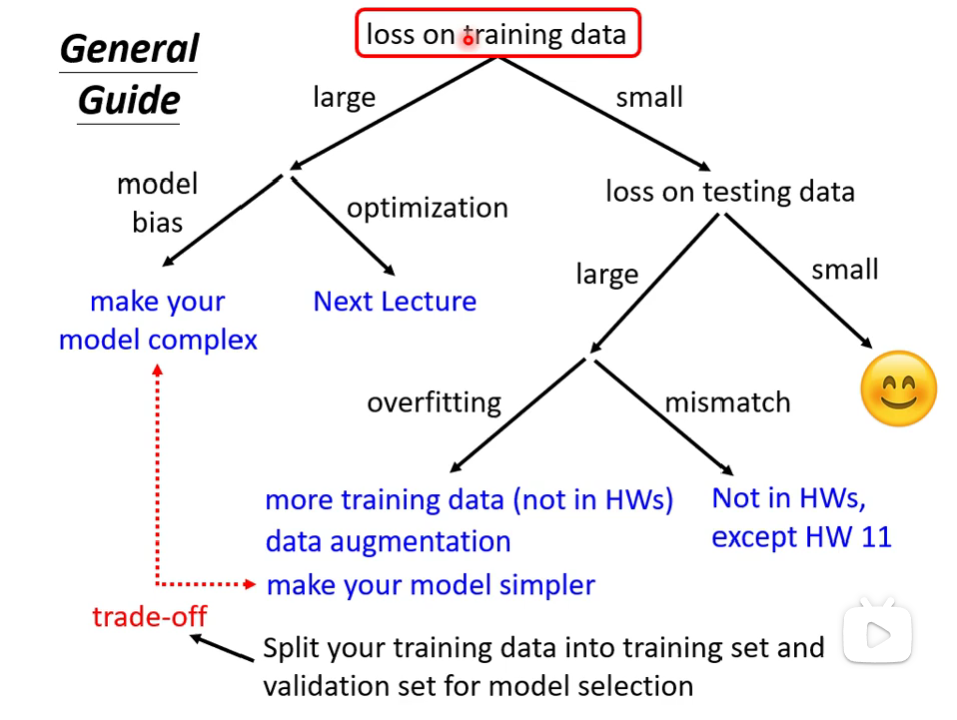
  首先观察训练数据上的loss大小,作出判断。
如果过大,可能是以下两个原因:
Model Bias
一般是因为模型过于简单,以至于找到的θ仅仅是function set里最小的,既不是局部最优解,也不是全局最优解。
解决办法:重新设计模型,让它更加具有弹性。例如增加输入的features、增加neurons神经元及layers层。
\par\par
Optimization
不知道模型是不是太简单了,得到的是否是局部最优解,但是可以肯定不是全局最优解。
解决办法:
- 通过比较不同的模型,从而得知设置的model是否足够大;
- 碰到从来没做过的问题时,先跑一些比较小的、比较浅的network;
- 在训练集上,如果深的model没有比浅的model获得更好的Loss,那就说明Optimization有问题.
/part/part
  如果过小,那就需要进一步看测试集了。在测试集上表现也小,那就没问题啦😊;如果表现大,就可能是如下两个原因:
Over fitting
解决办法:
增加训练资料;
数据强化:在视觉处理里,可以左右翻转、放大截取一部分等等,但是要合理,不能颠倒图片;
限制模型,不让它有太大的弹性。例如:更少的参数,参数共享;更少的特征;正则化;Early stopping;Dropout等等.
Mismatch
训练集和测试集分布是不一样的,这种情况下再增加训练资料也没办法改变。(这个我真不会😔)