还没写好
1.基本介绍
Generative Adversarial Network(GAN)生成对抗网络
把network作为generator,在原有输入的基础上,加入random的vector$\boldsymbol z$,它有两个限制:①随机;②足够简单
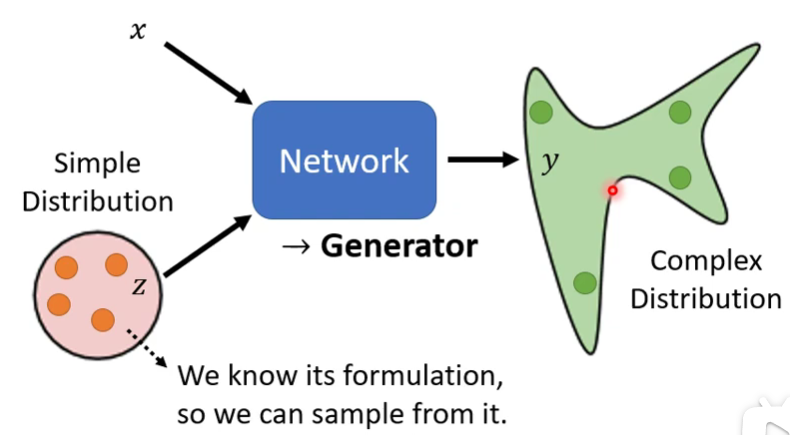
(1)为什么需要generator?
同样的输出会有不同的输出的时候,特别是某些任务需要“创造力”的时候。例如说走路,是向右还是向左呢?
(2)GAN的种类
非常多,具体可以参见https://github.com/hindupuravinash/the-gan-zoo
1.1Unconditional Generator
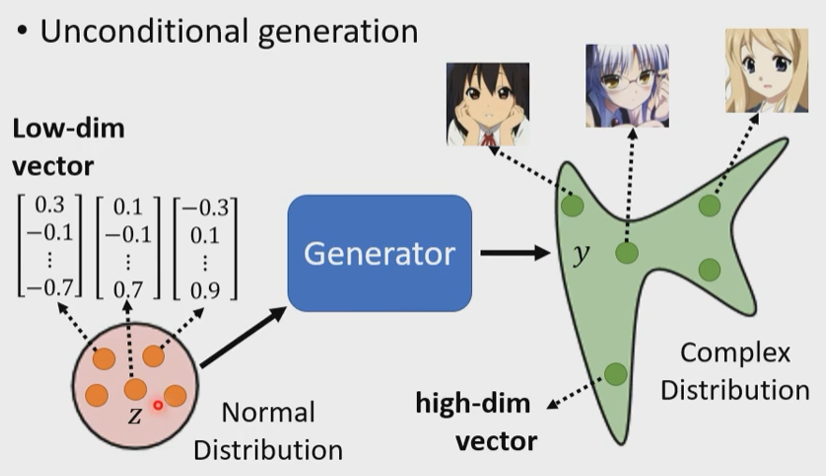
Discriminator鉴别器
算法如下:
初始化Generator生成器和Discriminator鉴别器
在每一个训练的迭代里:
①固定生成器G,更新鉴别器D
②固定鉴别器D,更新生成器G
……
一个固定住,另一个更细,下一次交换更新和固定的对象,反复训练它们
2.理论介绍与WGAN
首先假设我们有一大堆的Normal Distribution,把它们丢到Generator里面去,然后会产生比较复杂的Distribution,称为$P_G$。另外,我们有一堆Data,这是真正的Data,称为$P_{data}$,它也形成了另外一个Distribution。我们希望这两个的形状越接近越好。图片的下方是一维的形象比喻。
其中的Div是$P_G$和$P_{data}$之间的差异。
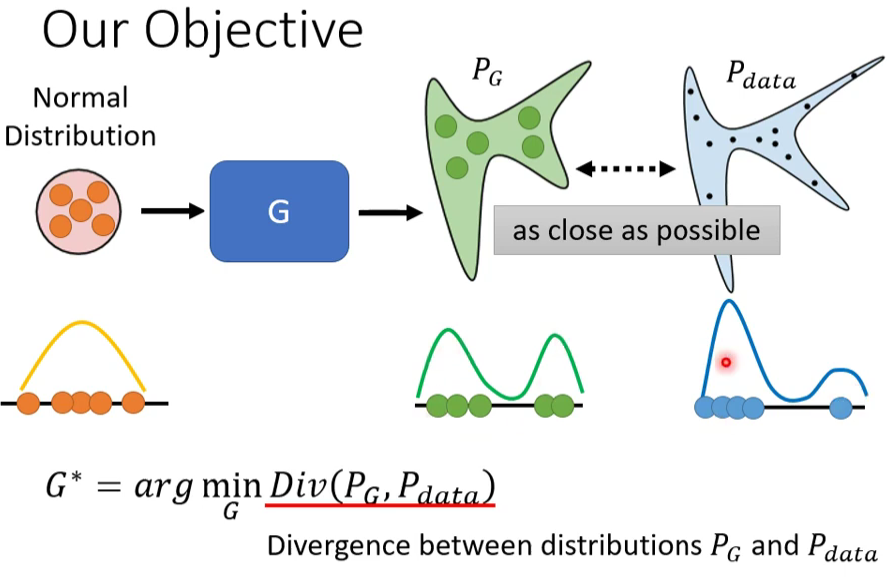 $$
\boldsymbol{G^*}=\arg \min \limits_{g} Div(\boldsymbol{P_G},\boldsymbol{P}_{data})\tag{1}
$$
## 2.1计算Div
$$
\boldsymbol{G^*}=\arg \min \limits_{g} Div(\boldsymbol{P_G},\boldsymbol{P}_{data})\tag{1}
$$
## 2.1计算Div
那我们要怎么计算这个Divergence呢?
可以根据取样来估算,从图库里随机sample一些图片出来,也就得到$\boldsymbol{P}_{data}$了;从 Normal Distribution 里sample一些vector出来,丢给Generator,产生一堆结果也就是$\boldsymbol{P_G}$。

在只做Sample的前提下,不能得知$\boldsymbol{P_G},\boldsymbol{P}_{data}$实际上完整的Formulation是什么,竟然也可以估测出Divergence,这个估测就需要Discriminator。相当于用神经网络训练了一个divergence的计算方式。

我们不知道怎么算Divergence,没关系,直接Train这个Discriminator,Train完以后,看他的Objective Function有多大,这个值就和Divergence有关。
那是不是意味着我可以用Discriminator替换掉这个Div,所以我们有了如下的Objective Function:
$$
\boldsymbol{G^*}=\arg \min \limits_{g} \max \limits_{D}V(G,D)\tag{2}
$$
看到上面的图片你可能会问为什么是JS divergence,而且还不是真的,仅仅是相关而已,怎么不用真正的JS divergence呢?或者不用别的呢?其实完全可以这么做,只要改了那个Objective Function,就可以用别的divergence了。至于怎么设计这个Objective Function,得到不同的divergence,可以参考以下文章。
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
2.2GAN的小技巧
GAN是以不好train而出名的,下面就讲一些训练GAN的小技巧
知名的WGAN
在讲WGAN之前,我们先来讲讲JS divergence有什么问题。
在大多数的情况下,$\boldsymbol{P_G},\boldsymbol{P}_{data}$重叠的部分往往非常少。理由有如下两点:
① 它们都是在高维空间中的低维空间流形。就像是二维空间中的两条线,除非是它们刚好重合,否则它们相交的范围几乎是可以忽略的。
② 我们从来不知道$\boldsymbol{P_G},\boldsymbol{P}_{data}$长什么样子,我们对它们分布的理解是来自于sample,也许它们有非常大的重叠部分,但是如果我们sample的点不够多。JS divergence有一个特性,就是两个没有重叠的分布,JS divergence算出来就永远是log2 。
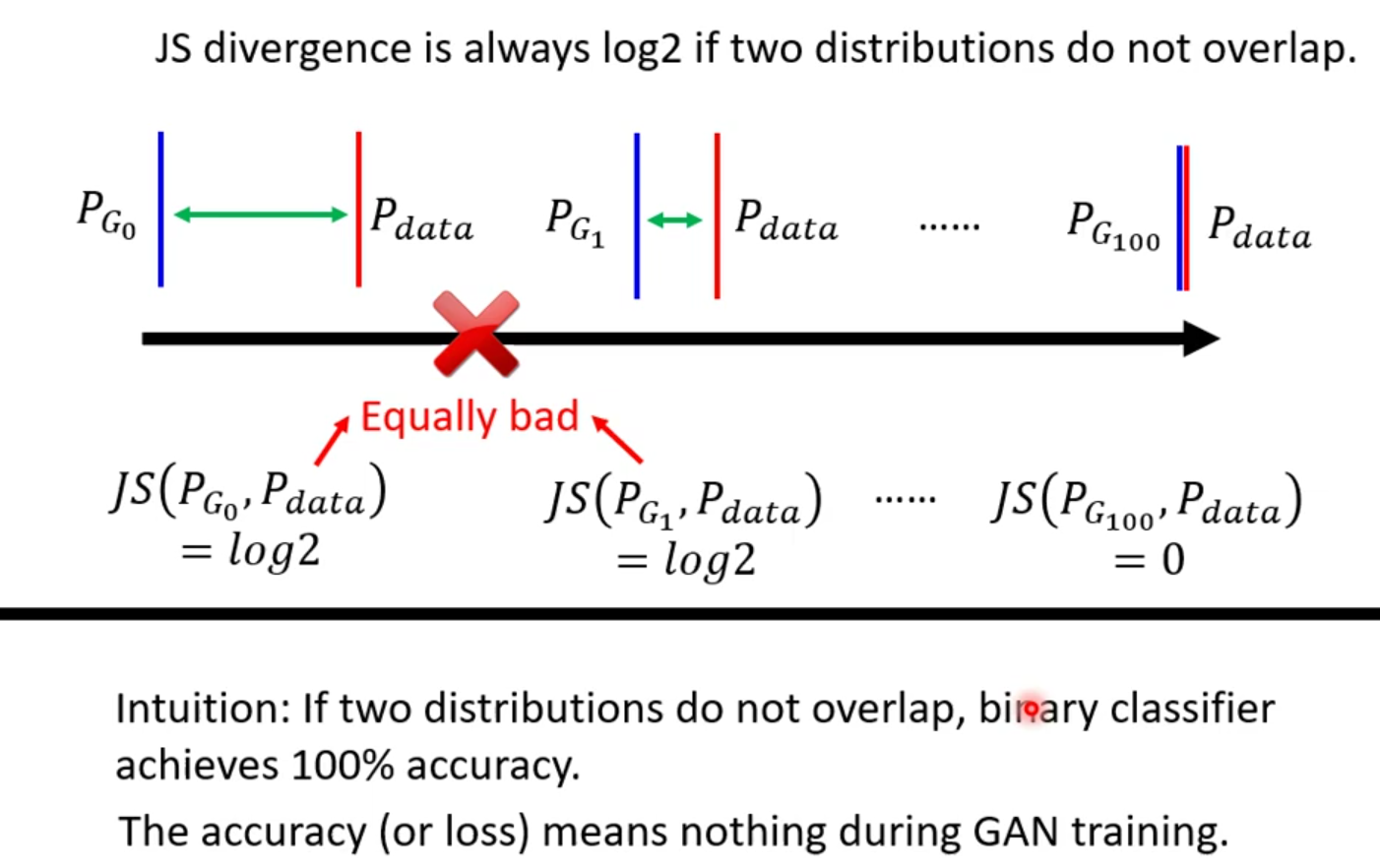
于是,WGAN就诞生了。
假设有两个distribution,一个是P,另一个是Q。想象你在开一台推土机,把P想象成一堆土,Q想象成土堆的目的地,从P到Q移动的平均距离就是Wasserstein distance。图中假设P和Q都集中到一个点上,那Wasserstein distance就是d。
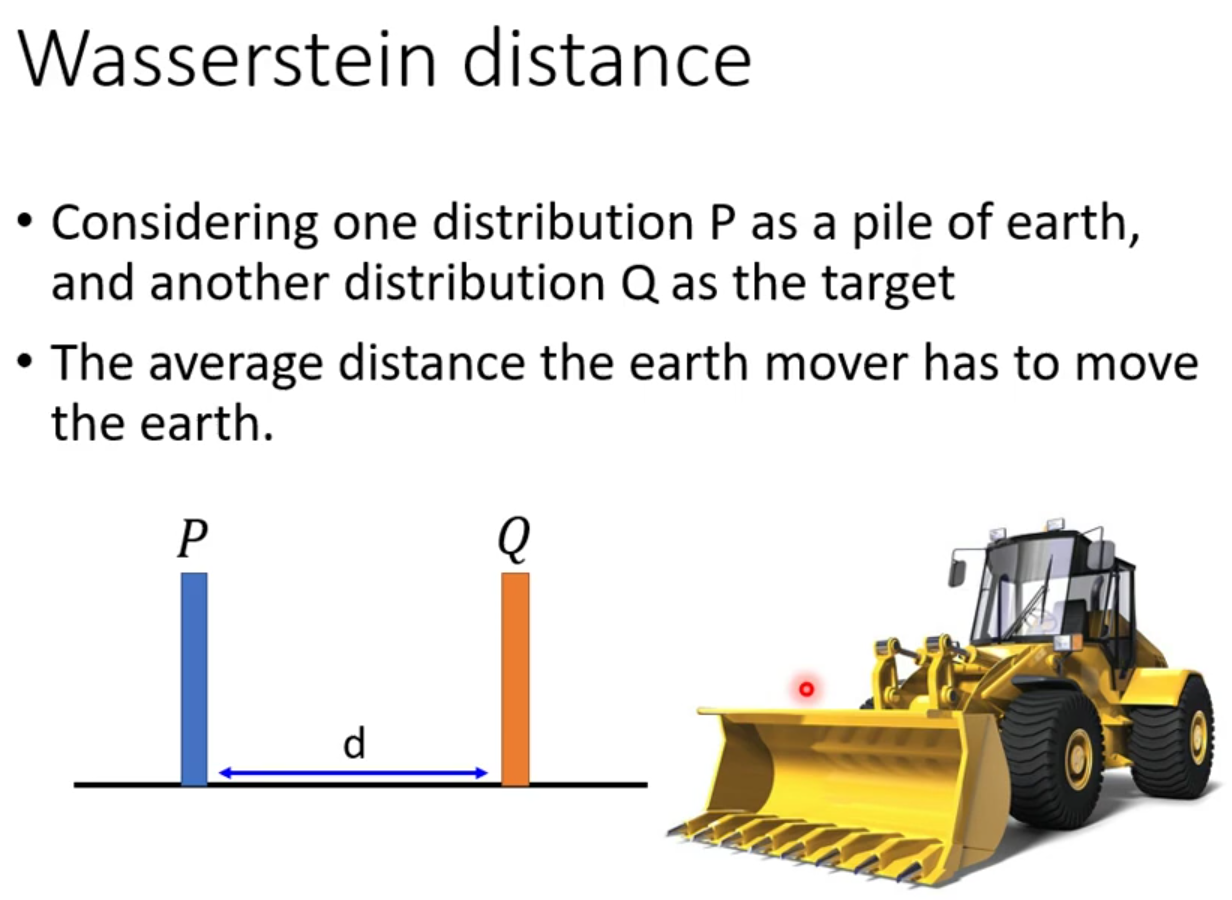
但是当我们考虑比较复杂的distribution的时候,就比如说如下图的“土堆”,是有很多种可能的“推土”方案的,那难道我们的Wasserstein distance也有无数多种吗?所以我们这里需要对它下定义,穷举所有Wasserstein distance,取最小的平均值就是Wasserstein distance。
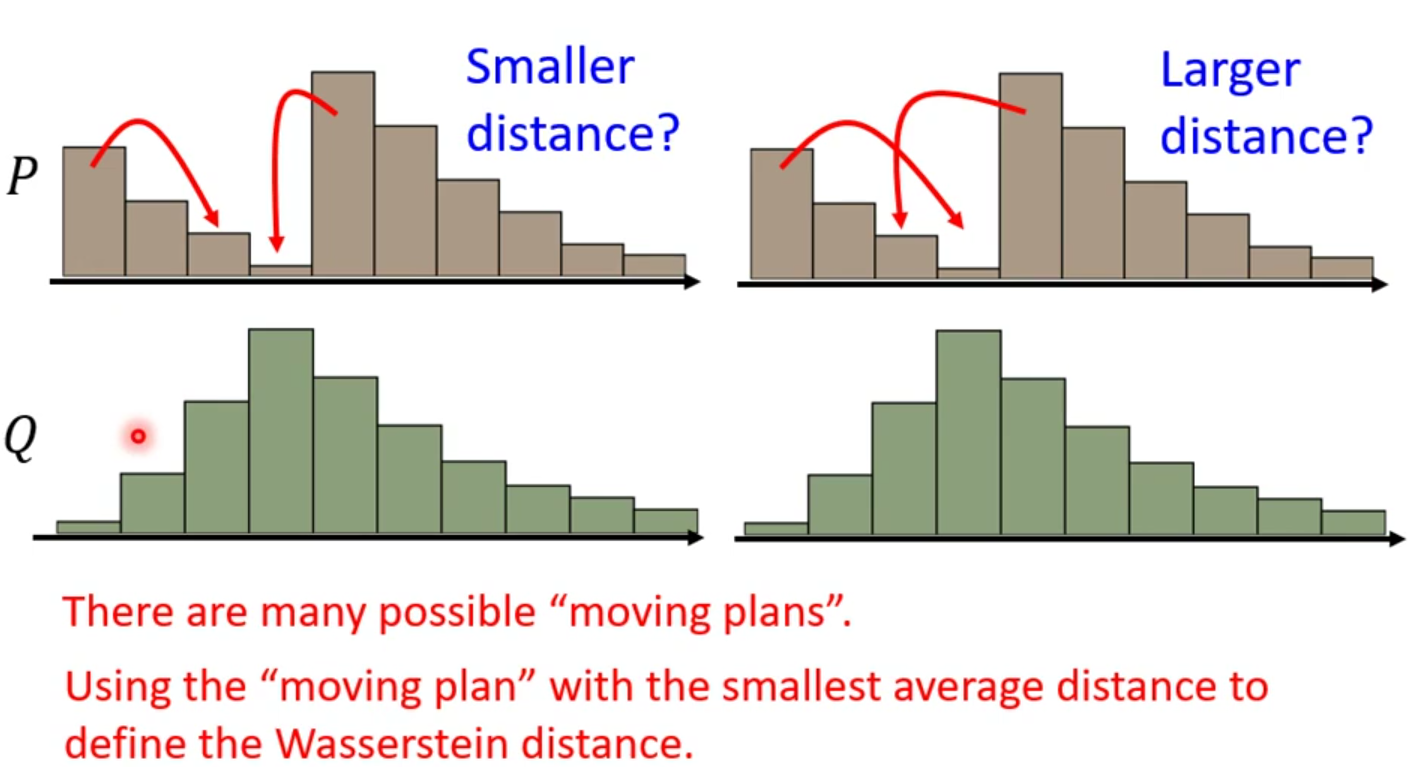
用式子表示出来就是
$$
\max_{D \in1 -Lipschitz} \left{ E_{x\sim P_{data}}[D(x)] - E_{x\sim P_G}[D(x)]\right} \tag{3}
$$
这个式子解出来就是Wasserstein distance。那如果我们要maximize这个式子,前项越大越好,后项越小越好。但是如果不对D的范围加一个限制,就会趋向于无穷,那就不会收敛了,无解。所以D要求属于利普希茨连续条件,也就是说必须要是一个足够平滑的函数。那这个范围到底应该怎么限制呢?
后面的稍微有点听不懂了捏。下面给出两篇paper作为参考
虽然有了WGAN,然而GAN训练起来还是比较困难的。因为有一个本质上的困难:就是Train的过程。GAN的训练过程,是Generator和Discriminator互相砥砺,相互进化的过程,只要其中之一发生了一点意外,停止了进化,那另外一个也将必然停止进化。假设在训练Discriminator的时候效果不是很好,就没有办法分辨好坏,Generator就失去了前进的目标;Generator没有办法再进步了,Discriminator也会跟着原地踏步。同时我们也不能保证一直训练下去就能得出很好的Loss函数。
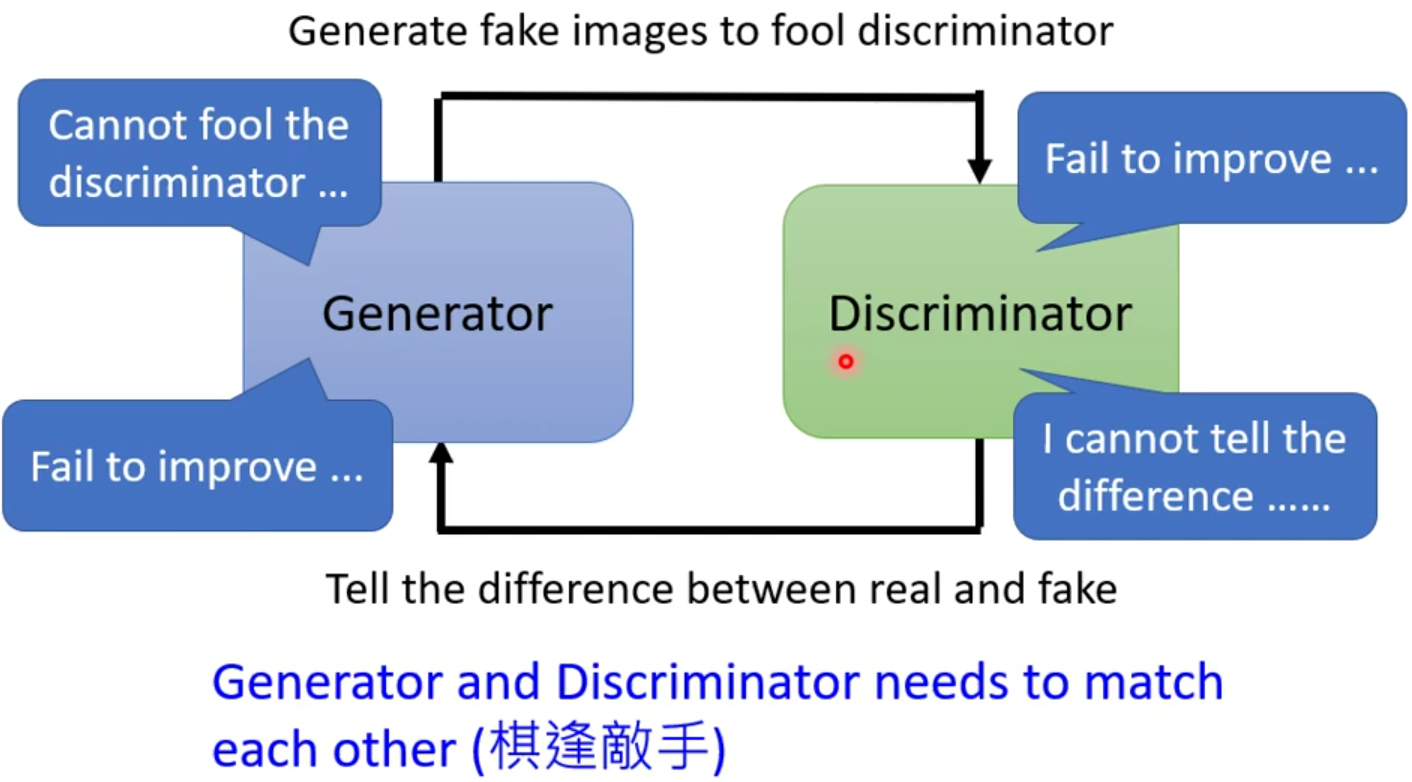
- 网络上其他的Tips
2.2GAN生成序列
训练GAN最难的其实是生成文字,如果要拿GAN来生成一段文字,会是最困难的。
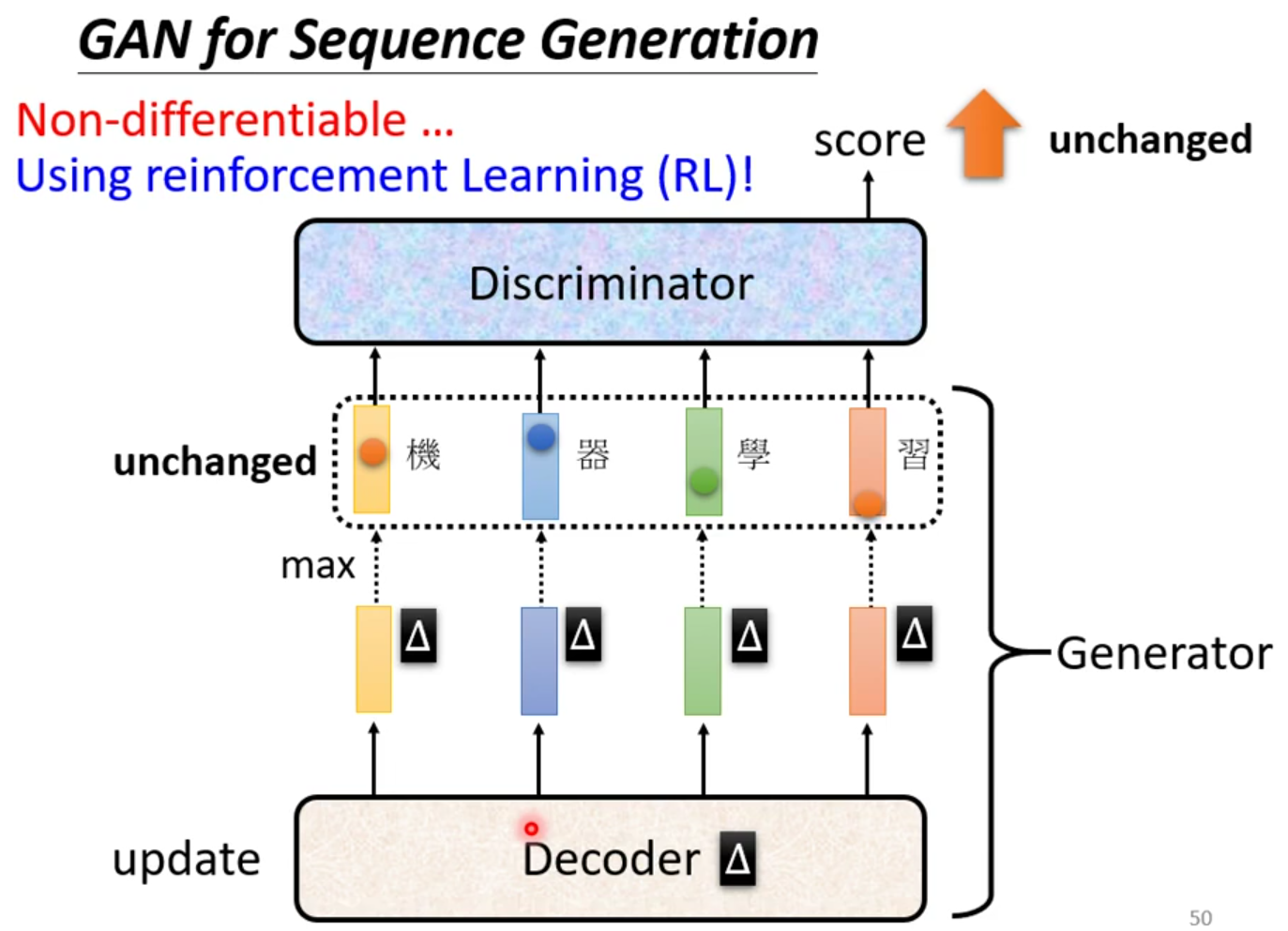
假设说你现在要生成一段文字,你会有一段seq2seq的模型,里面有一个Decoder,它来负责产生一段文字,这一整个就是我们的Generator。接下来把生成的文字依旧是放到Discriminator里,然后打分,循环训练。现在是不是还没发现他难训练在哪里。
我们知道,如果我们要用gradient decent去训练我们的decoder,使得输出的分数越大越好,但是我们是做不到的。我们在做gradient decent的时候,其实做的是计算微分,某一个参数他有变化的时候,对目标造成的影响就是这个gradient。现在我们假设Decoder有一个小小的变化,那它输出的distribution也会有一点小小的变化,但是因为他很小,这个变化对于max而言基本就是没有。最终输出的token就没有发生改变,那输出的分数就没有改变。
当然,除了GAN,还有其他的Generative Models,例如:变分自编码器(Variational Autoencoder,VAE),基于流的生成模型(FLOW-based Models),还有扩散模型。
3.GAN的评价标准
怎么去评价生成的结果呢?最直接的做法那肯定是找人来看啊!!就比如我们毕业设计的时候,直接跟评委老师说,我觉得我的比它的好(大误)
- 人类评测花费较昂贵,还有可能不公平、不稳定。
- 如何自动地去评价生成的质量呢?
有一个方法是跑一个影像的分类系统,把产生出来的图片丢到这个分类系统里,看他产生什么样的结果。通常,输入的图片设定为y,输出的是一个概率分布。如果说这个概率分布越集中,可能代表着图片质量越好;如果概率是平均分布的,说明产生出来的图片比较奇怪。
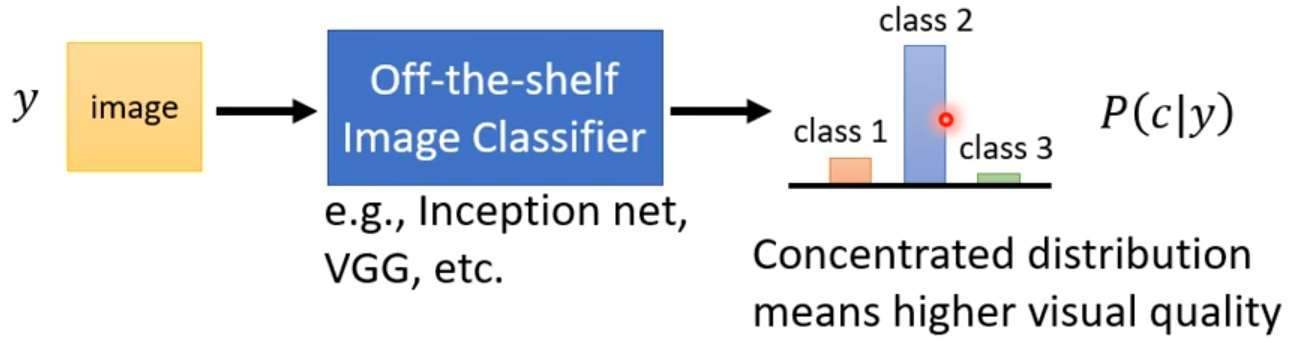
但是,光用这个做法会出现一个问题,会出现Mode Collaapse。
Mode Collaapse
就是你有时候训练可能会遇到一种状况,就是生成模型输出的图片一直在重复出现。假设就是那里有一个盲点,当generator学会生成盲点的图片的时候,它就可以一直欺骗discriminator,这种现象就称为Mode Collaapse。


Mode Dropping
这是一种比Mode Collaapse更加难被发现的现象,单纯看产生出来的图片你可能会觉得还不错,而且分布的多样性也够 。但是真实的资料其实分布性是更大的。

多样性检验
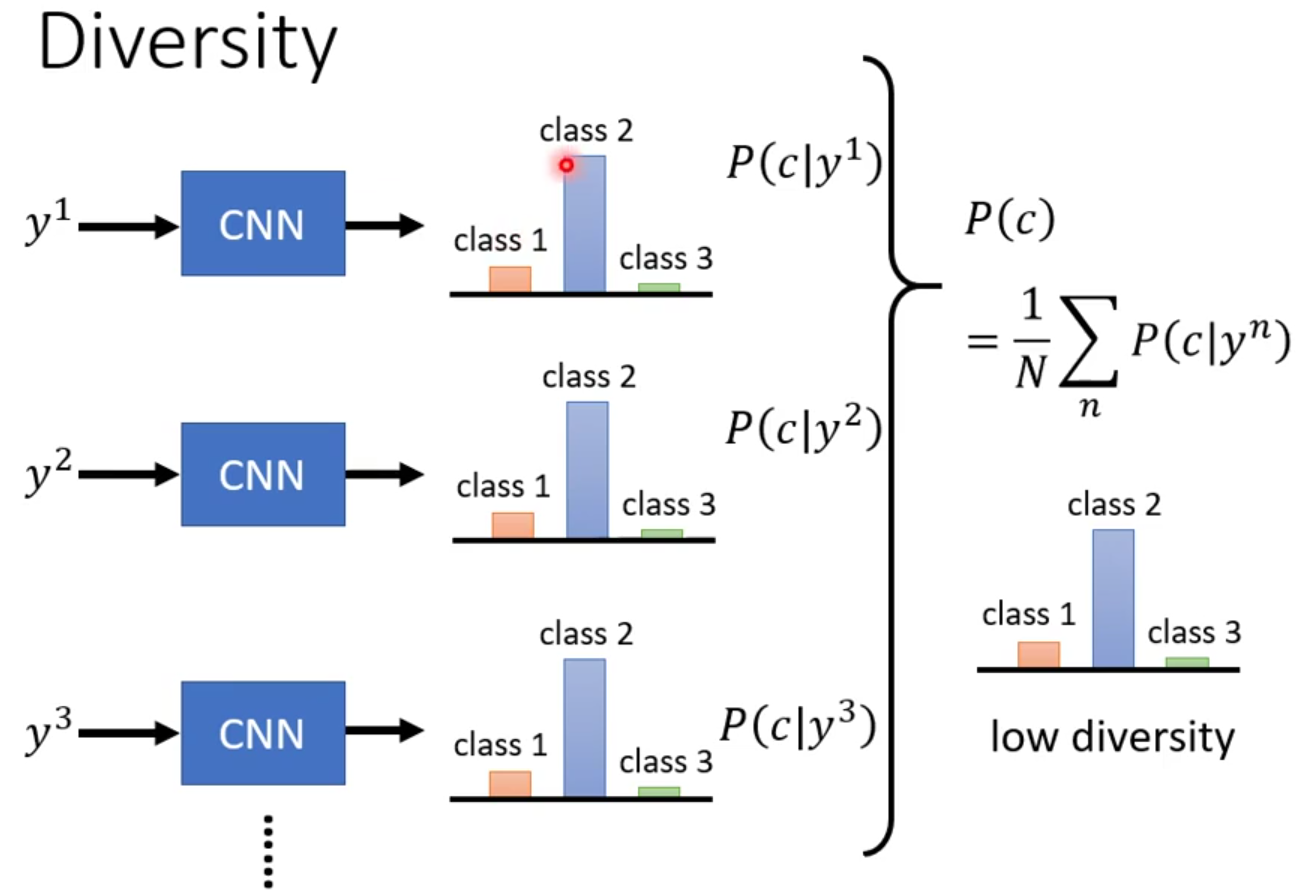
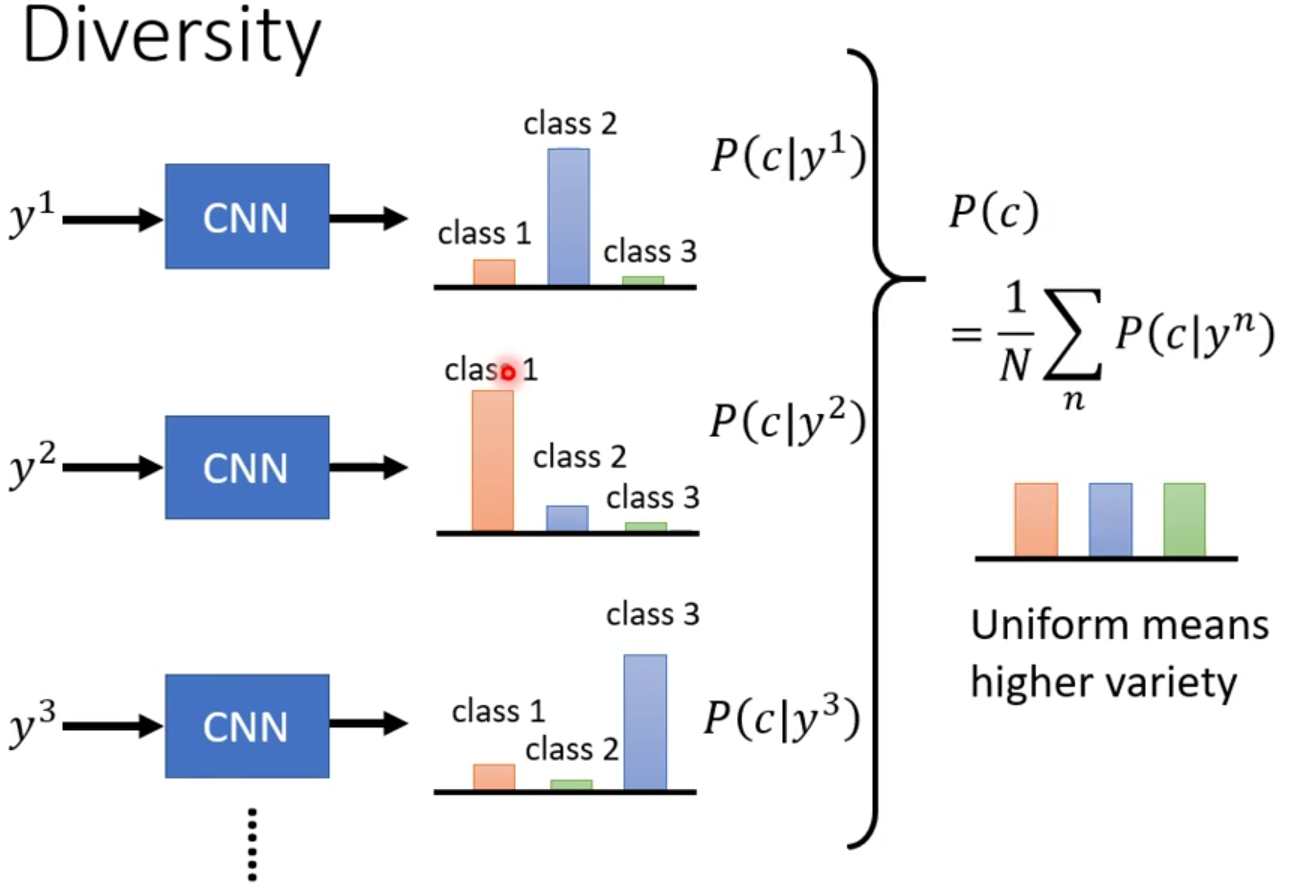
平均分布检验,做法如下:
- 把产生出来的图片都丢到图片分类器里面,看他被判断成哪一个类别,
- 每张图片最后都将输出一个分布,把所有的分布进行平均,看看最终的分布长啥样。
- 如果是平坦的,那就说明多样性不够;如果比较平坦,那么多样性可能是足够的。
但是这样做以后就和我们上面所说的“概率分布越集中,可能代表着图片质量越好”矛盾了。不过这里它们评估的范围不一样,质量评估的范围是一张图片,多样性评估范围是全部图片。
FID
在分类任务中,先把产生出来的图片丢到Inception Net里边,然后取进入softmax之前的隐藏层的向量作为这张图片的代表,softmax之后的归到类别是虽然都是一样的,但是取出来的这个向量可能还是不一样的。所以我们不取最后的这个类别,只取最后一层隐藏层的输出来代表这一张图片。
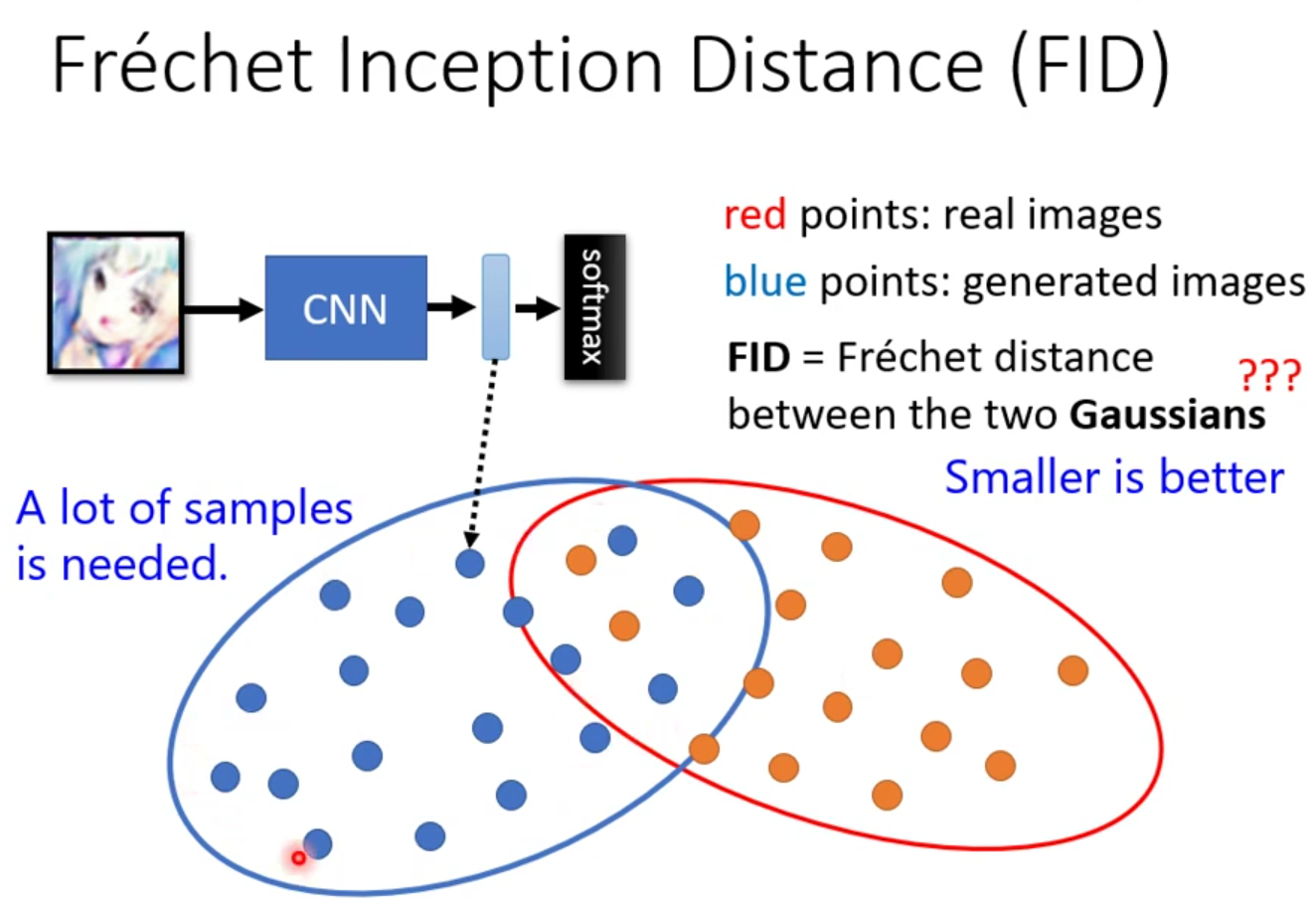
假设这一堆点都是符合高斯分布,然后就去计算这俩高斯分布的Fréchet distance。那因为他是一个距离啦,所以是越小越好,代表着这两组图片越接近,产生出来的品质也就越高。
但是这只是我们的假设罢了,是的,还真的会有问题。
如果你要准确地得到network的分布,那就需要大量的样本。就需要大量的运算量。
好,光说问题,都没有说到什么评价标准。其实这也可以算是一个研究的领域了。因为如果你的generator产生出来的图片和你的样本是一模一样的,那他的多样性啦,FID啦都会得到很好的结果,但是这不就等于训练了个寂寞吗?如果产生出来的图片是把原图片左右反转了一下然后输出,那这样得到的FID也会很好,这同样也没有达到我们的要求。
4.Conditional Generation
从本文章开篇至今,输入的都是一个随机的分布。
4.1Text2image
参考论文:https://arxiv.org/abs/1605.05396
现在我们更进一步,我们想要操控Generator的输出,我们给它一个condition x,它和输入z同时控制输出y。它可以应用于Text2image。如此一来就相当于是监督学习了。
那我们要如何去做这个GAN呢,如果我们还像之前的那样用一个Discriminator去辨别产生出来的图片,然后给我们返回一个值,用来映射产生出来的图片是否真实的图片,那,确实Generator会学习如何产生真实的图片,但是会完全无视输入的条件。显然这不是我们想要的结果。
所以我们需要改进这个Discriminator。我们同时把x和y作为Discriminator的输入,然后就会输出一个数值。只有在输出的图片质量好,还要和图片的描述相匹配才能得到一个比较大的数值。
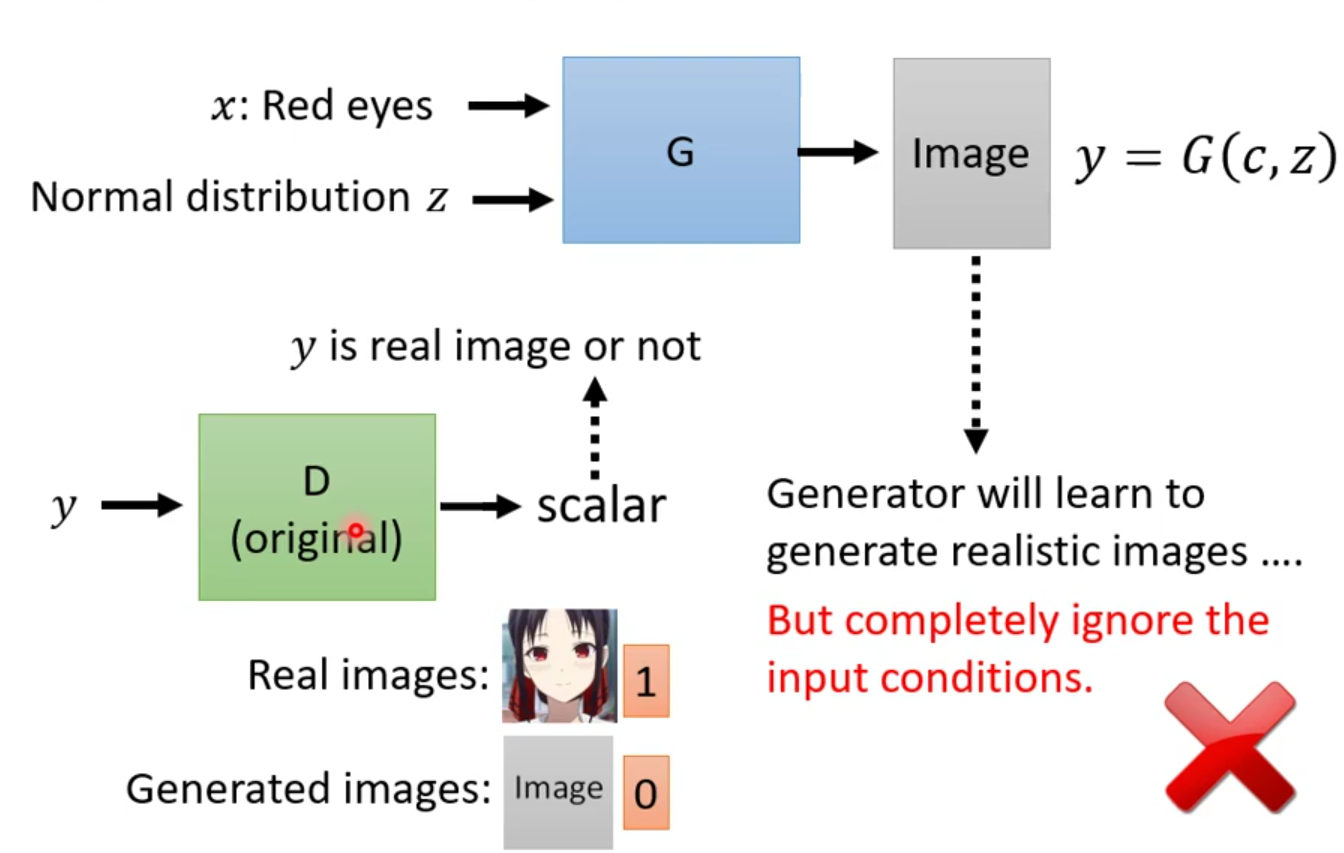
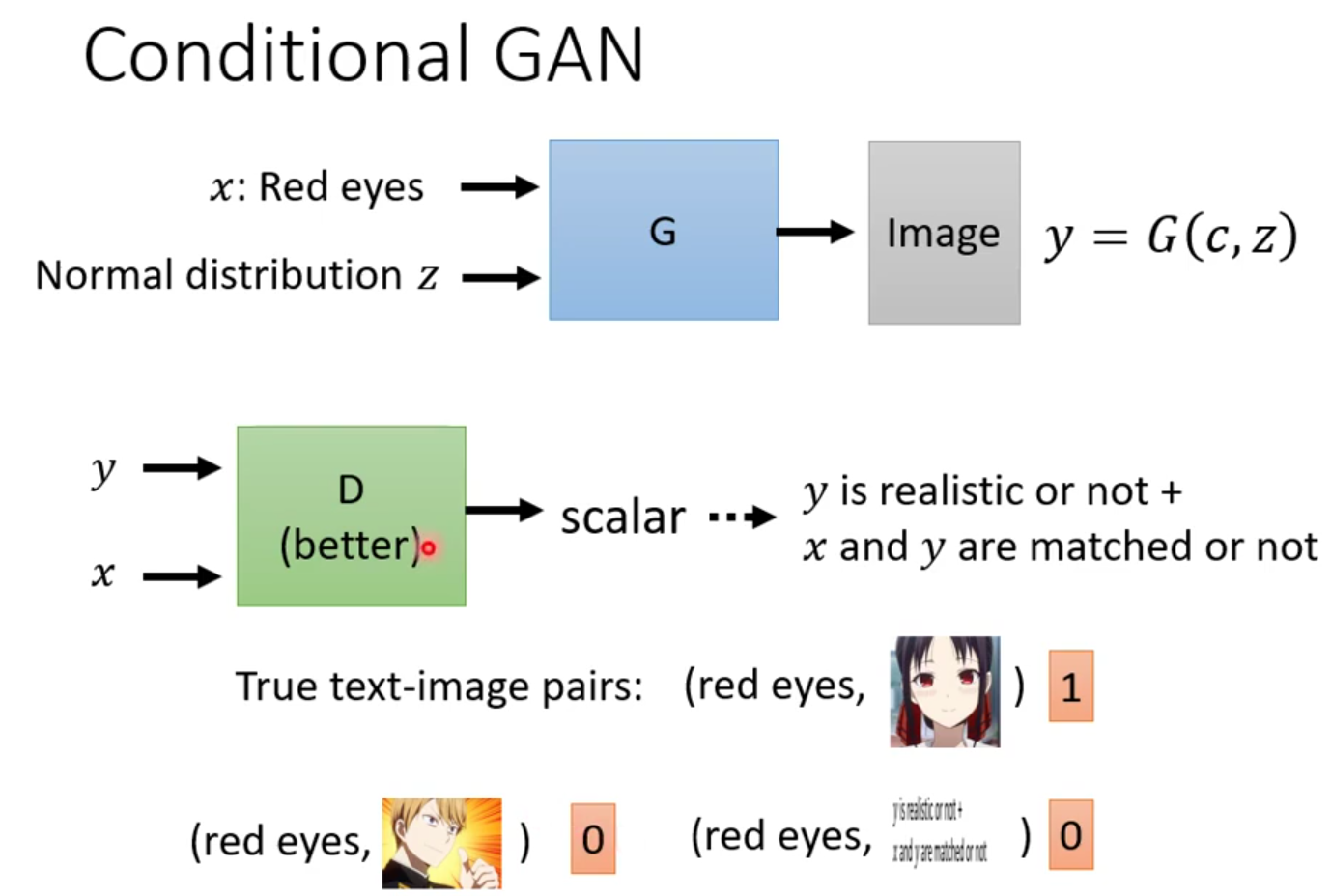
那这个Discriminator也不是无中生有的,需要经过训练才有。训练的资料需要有文字和图片成对的,看到既是red eyes又是真实图片就给1分;看到是red eyes但不是真实图片给0分;看到真实的图片但是和red eyes不匹配的也要给0分。
4.2pix2pix
参考论文:https://arxiv.org/abs/1611.07004
除了拿去做文字转图片,还可以有图片生图片。例如说给一张标签图,它把图片补全;给一张黑夜的图片,变成白天的图片;给一张黑白图片,变成彩色的图片;给一张真实的俯视图,变成一张地图;给他一张素描,补全成完整的图。
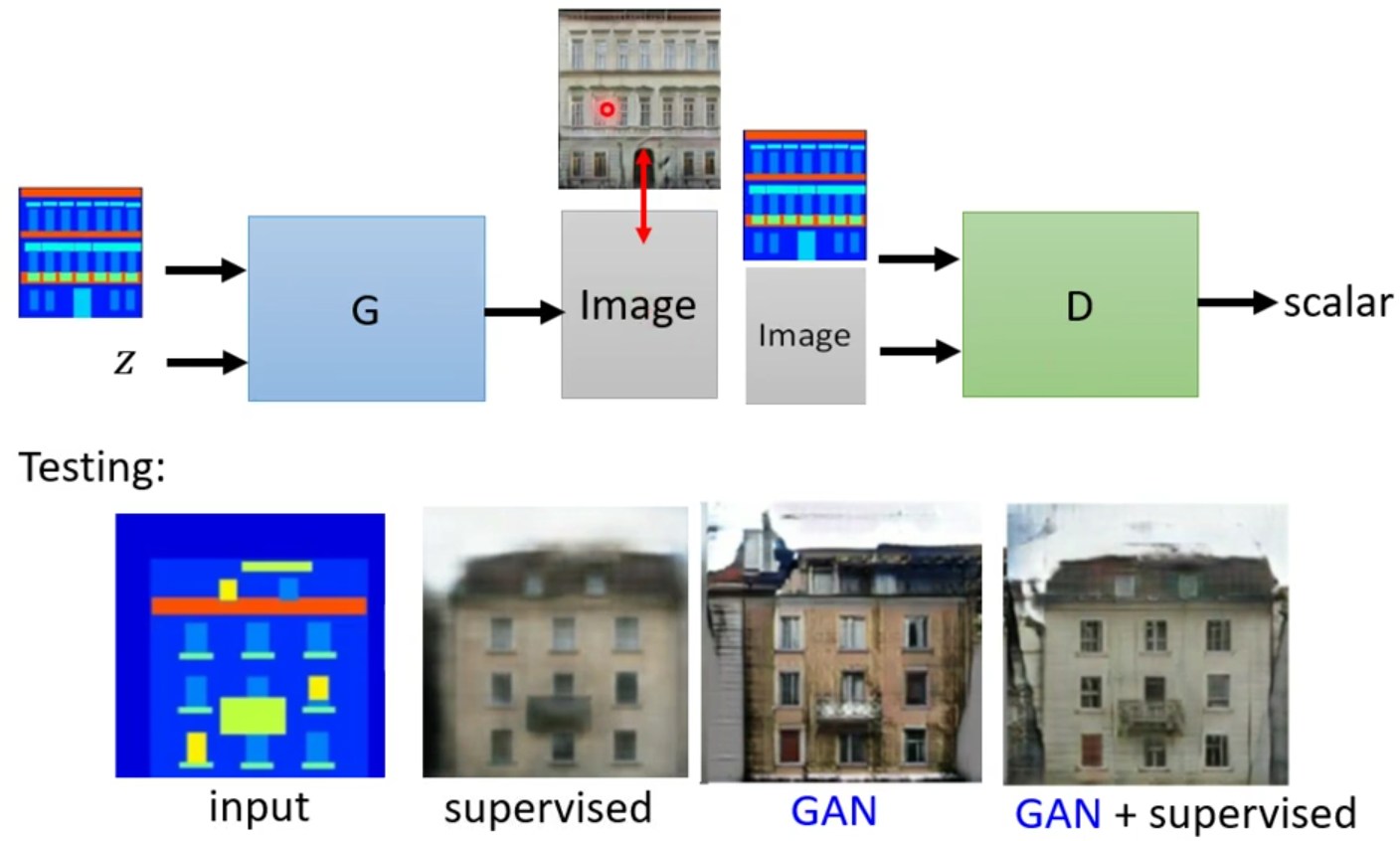
但是在做的时候就会发现啊单独用监督学习或者单独GAN的效果并不理想,有人就发现说两个一起做效果就会很好。
4.3sound2img
参考项目:https://wjohn1483.github.io/audio_to_scene/index.html
根据听到的声音去产生一张图片,例如听到狗叫声就产生一张狗狗的图片。训练的资料就很多啦,视频就自带这个效果。
5.应 用
到目前为止,都是把GAN用到监督学习中的
把GAN用在非监督学习上,cycle